2024년 엔비디아(NVIDIA)의 특허 출원 동향 분석
파인특허
2024. 9. 30.
엔비디아(NVIDIA)는 인공지능(AI), 그래픽 처리 장치(GPU), 자율주행, 데이터센터 등 다양한 분야에서 기술 혁신을 이끌고 있는 글로벌 기술 기업입니다. 특히, GPU 기술을 통해 게임, AI, 클라우드 컴퓨팅, 자율주행 차량 등 여러 산업 분야에서 중요한 역할을 하고 있습니다. 엔비디아의 특허 출원 분석을 통해, 엔비디아가 어떻게 기술 혁신을 주도하고 있는지 확인해보겠습니다.
엔비디아 특허 출원 데이터를 분석하기 위해 AP:(NVIDIA) 키워드를 키워트(keywert)를 사용하여 검색을 진행하였으며, 중복 제거를 통해 최종적으로 확인된 데이터는 다음과 같습니다.
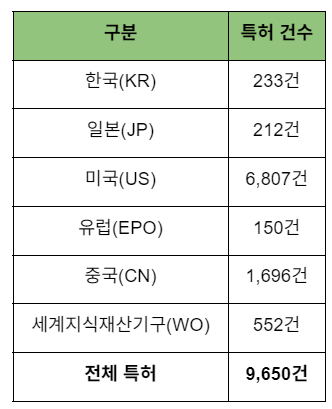
이와 같은 검색 방법을 통해 2024년 9월30까지의 엔비디아의 글로벌 특허 출원 현황을 파악하였습니다.
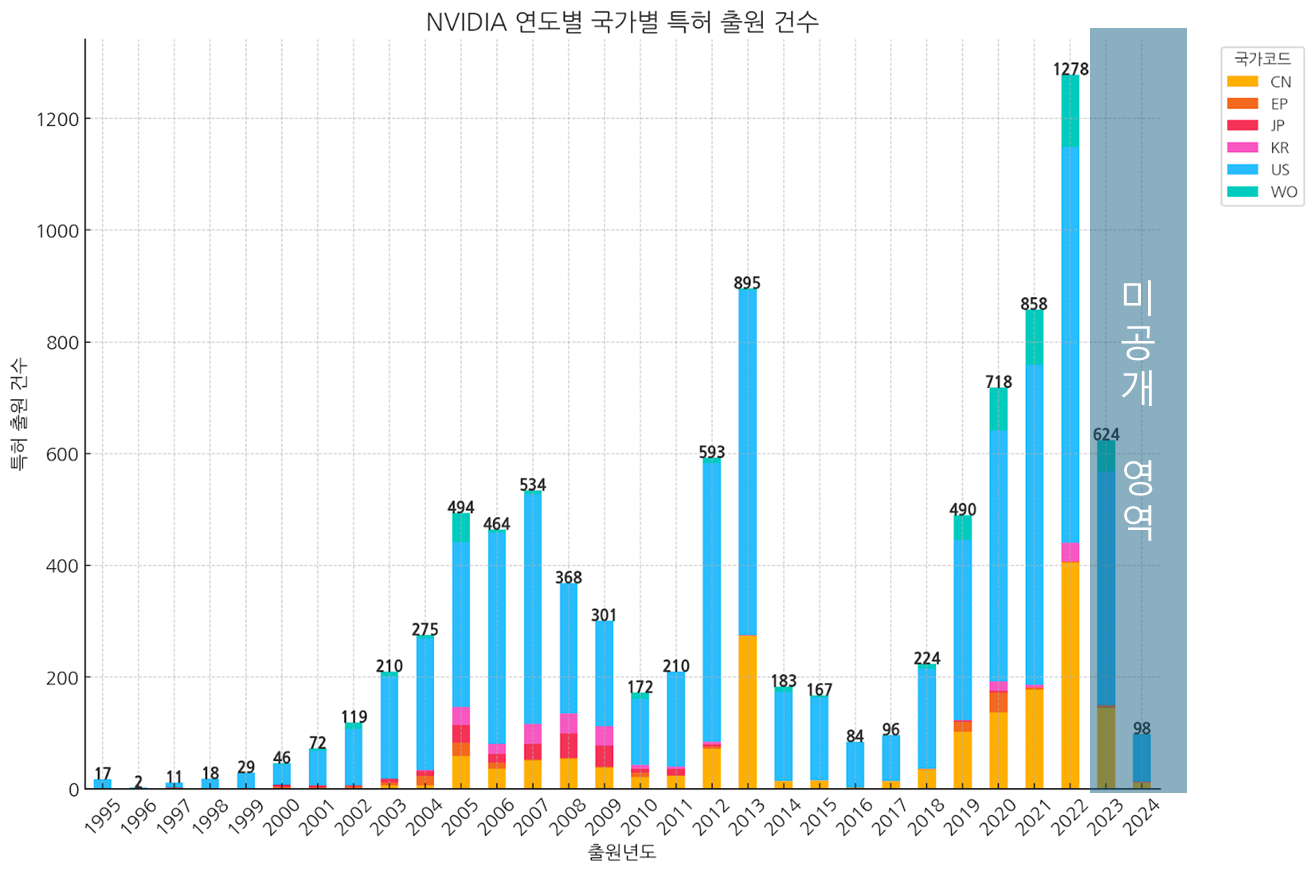
1995년~1999년:
2000년대 초반 (2000~2005년):
2010년대 초반:
2010년대 중반 이후:
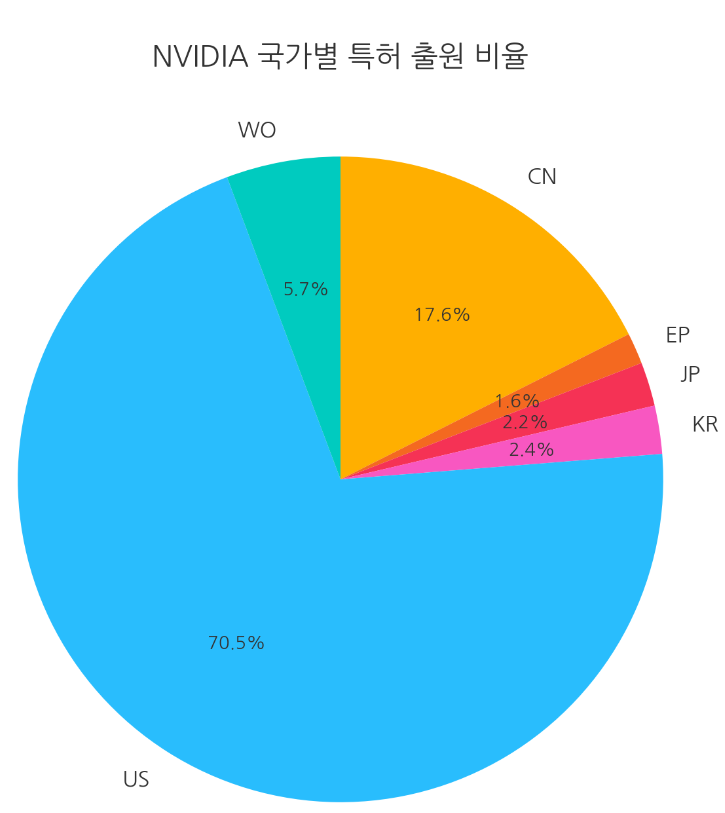
NVIDIA의 국가별 특허 출원 비율을 나타내며, 국가별 출원 건수는 다음과 같습니다:
미국이 전체 출원에서 가장 큰 비중을 차지하고 있으며, 중국과 국제 출원이 그 뒤를 따릅니다.
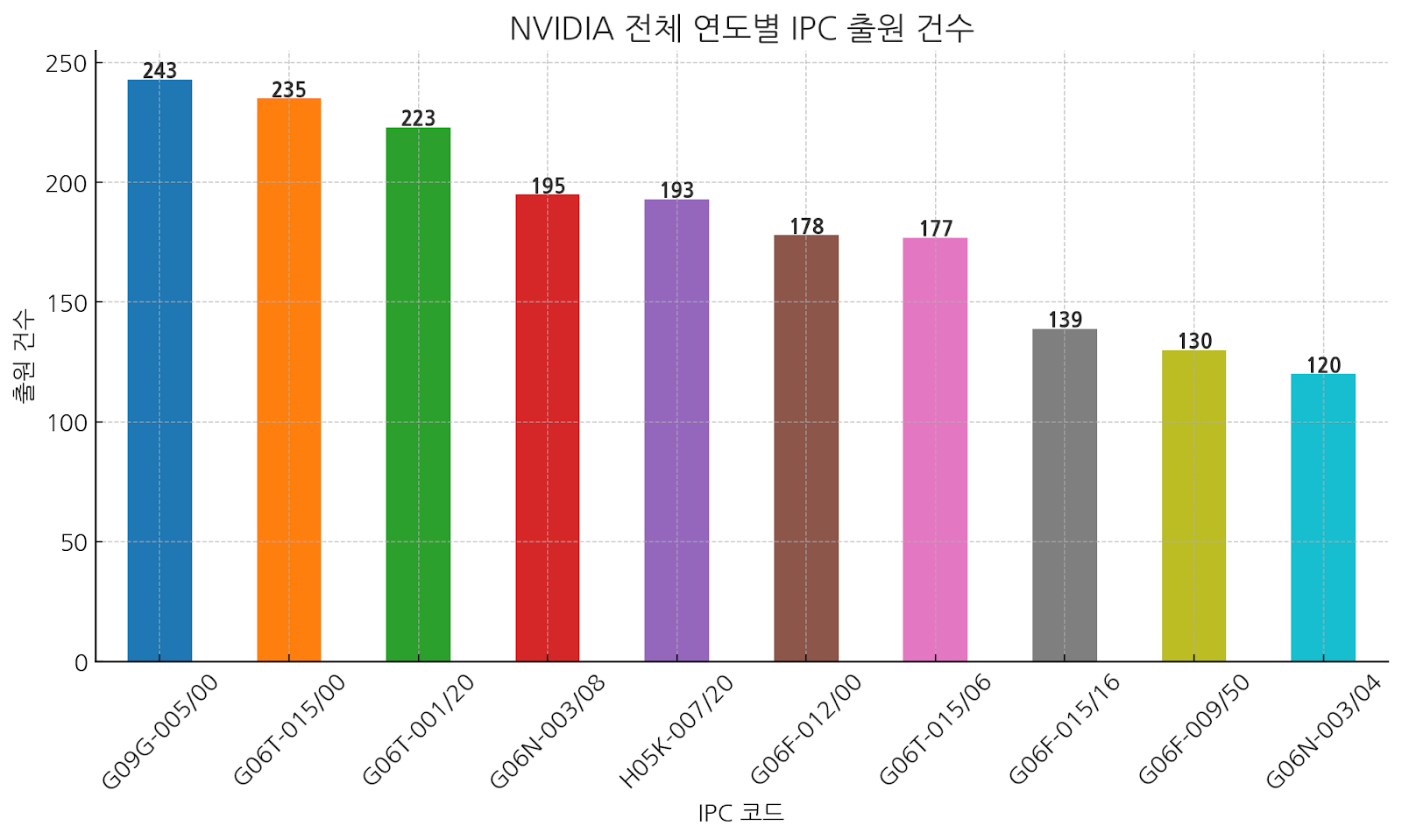
NVIDIA는 그래픽 처리, AI, 머신러닝, 데이터 처리, 사용자 인터페이스 등의 다양한 분야에서 기술 리더로 자리 잡고 있으며, 이러한 핵심 기술들이 출원된 특허에 반영되어 있습니다. 특히, GPU 성능 향상과 AI 및 3D 그래픽 기술의 발전에 많은 공을 들이고 있음을 알 수 있습니다.
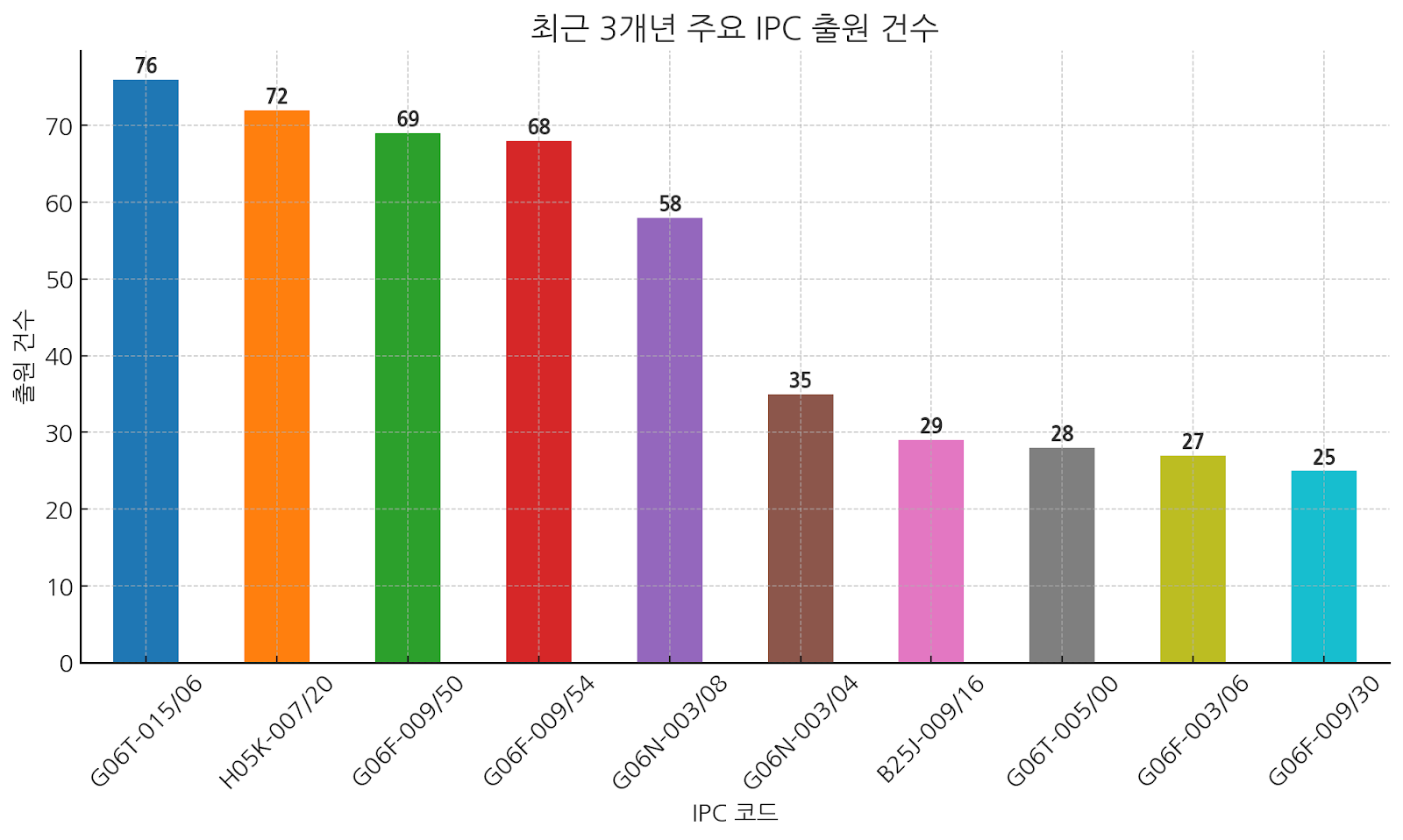
최근 3년간 NVIDIA는 그래픽 처리, 인공지능, 신경망 학습, 병렬 연산과 관련된 핵심 기술에 중점을 두고 특허를 출원하고 있습니다. 특히, 고성능 컴퓨팅과 열 관리, 이미지 처리, AI 기반 신경망 기술은 NVIDIA의 미래 기술 전략에 큰 비중을 차지하고 있으며, 다양한 산업 분야에서 이 기술들을 적용하려는 노력이 엿보입니다.
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from nltk.tokenize import RegexpTokenizer
from nltk.corpus import stopwords
import matplotlib.pyplot as plt
import numpy as np
import nltk
# NLTK 불용어 다운로드
nltk.download('stopwords')
# 특허 문헌에서 자주 사용되는 불용어 세트 정의
patent_stopwords = set([
'method', 'apparatus', 'system', 'device', 'means', 'include', 'comprising', 'claim', 'wherein',
'invention', 'embodiment', 'embodiments', 'described', 'present', 'application', 'may', 'can',
'one', 'said', 'use', 'used', 'step', 'steps', 'provide', 'providing', 'example', 'plurality',
'first', 'second', 'third', 'according', 'thereof', 'therein'
])
# 불용어 세트 (일반 영어 불용어 + 특허 관련 불용어)
stop_words = set(stopwords.words('english')).union(patent_stopwords)
# 텍스트 전처리 함수 정의
tokenizer = RegexpTokenizer(r'\w+')
def preprocess(text):
tokens = tokenizer.tokenize(text.lower()) # 소문자로 변환 후 토큰화
filtered_tokens = [word for word in tokens if word not in stop_words and len(word) > 2] # 불용어 및 짧은 단어 제거
return ' '.join(filtered_tokens)
# 데이터 로드
file_path = 'nvidia_en.xlsx'
data = pd.read_excel(file_path)
# 발명의 명칭과 요약을 결합한 텍스트 칼럼 생성
data['combined_text'] = data['발명의 명칭'].astype(str) + ' ' + data['요약'].astype(str)
# 텍스트 전처리
data['processed_text'] = data['combined_text'].apply(preprocess)
# 벡터화 (CountVectorizer 사용)
vectorizer = CountVectorizer(max_df=0.95, min_df=2, stop_words='english')
text_vectorized = vectorizer.fit_transform(data['processed_text'])
# 다양한 토픽 개수에 대해 LDA 모델을 학습하고 perplexity 값 계산
perplexities = []
topic_range = range(2, 21) # 2~20개의 토픽 시도
for num_topics in topic_range:
lda = LatentDirichletAllocation(n_components=num_topics, random_state=42)
lda.fit(text_vectorized)
perplexities.append(lda.perplexity(text_vectorized)) # perplexity 저장
# 토픽 개수에 따른 perplexity 그래프 그리기
plt.figure(figsize=(10, 5))
plt.plot(topic_range, perplexities, marker='o')
plt.xlabel("Number of Topics")
plt.ylabel("Perplexity")
plt.title("Perplexity by Number of Topics")
plt.show()
# 최적의 토픽 개수 선택
optimal_num_topics = topic_range[perplexities.index(min(perplexities))]
print(f"Optimal number of topics: {optimal_num_topics}")
# 최적의 토픽 수로 LDA 모델 학습
lda_final = LatentDirichletAllocation(n_components=optimal_num_topics, random_state=42)
document_topics = lda_final.fit_transform(text_vectorized)
# 상위 단어 출력 함수 정의
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print(f"Topic {topic_idx+1}:")
print(" ".join([feature_names[i] for i in topic.argsort()[:-no_top_words - 1:-1]]))
# 최종 토픽 모델의 상위 10개 단어 출력
no_top_words = 10
tf_feature_names = vectorizer.get_feature_names_out()
display_topics(lda_final, tf_feature_names, no_top_words)
# 각 문서가 가장 많이 할당된 토픽을 계산 (가장 높은 확률의 토픽)
dominant_topic_per_doc = np.argmax(document_topics, axis=1)
# 토픽별 문서 개수 계산
topic_counts = np.bincount(dominant_topic_per_doc, minlength=optimal_num_topics)
print("\nTopic Counts (Number of documents assigned to each topic):")
for i, count in enumerate(topic_counts):
print(f"Topic {i+1}: {count} documents")위의 토픽 분류 알고리즘을 통한 토픽별 출원 건수는 다음과 같습니다.
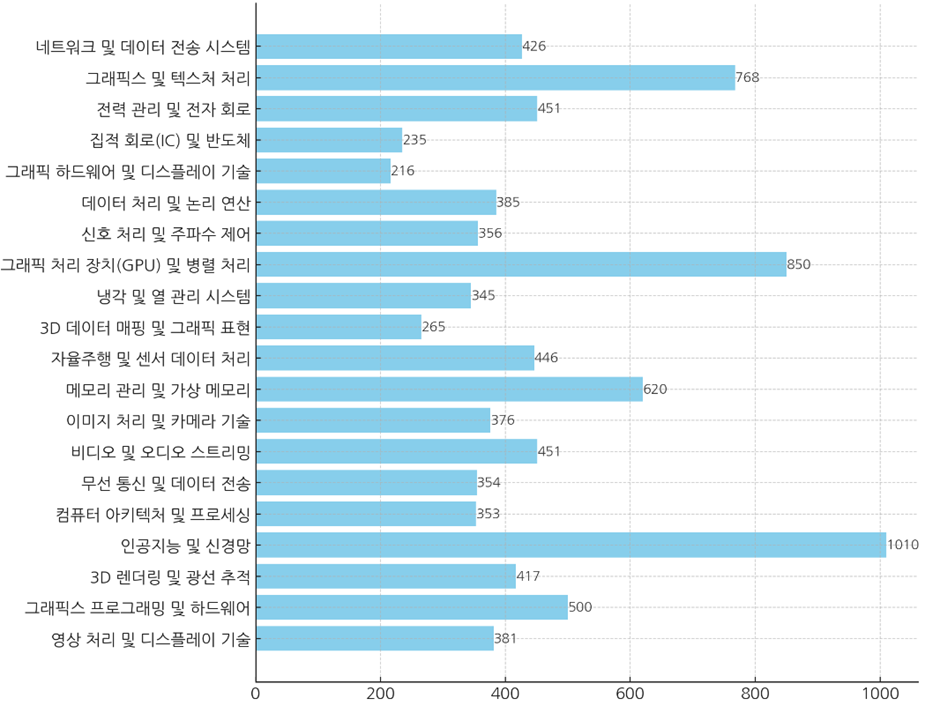
엔비디아의 토픽별 출원 건수 데이터를 바탕으로 설명드리겠습니다.
기타 분야는 각각 약 200~400건 정도의 출원 건수를 보이고 있으며, 이는 엔비디아가 다양한 하드웨어 및 소프트웨어 기술을 광범위하게 개발하고 있음을 보여줍니다.
엔비디아의 특허 출원 데이터를 분석한 결과, 이 회사는 그래픽 처리 장치(GPU), 인공지능(AI), 병렬 처리 기술 등 다양한 첨단 기술 분야에서 꾸준히 혁신을 이어가고 있음을 확인할 수 있습니다. 특히, 엔비디아는 GPU 기술을 중심으로 인공지능, 자율주행, 데이터센터 등 여러 산업 분야에서 중추적인 역할을 하고 있으며, 이는 특허 출원 수와 범위에서도 명확히 드러납니다. 최근 3년간의 데이터에서는 AI와 이미지 처리, 병렬 연산 기술이 주요 연구 영역임을 알 수 있었으며, 글로벌 시장에서의 입지를 확대하기 위한 다양한 특허 전략이 뒷받침되고 있음을 볼 수 있었습니다. 이러한 기술적 리더십은 엔비디아가 향후 다양한 산업에서 혁신을 주도하고, 기술 발전에 중요한 역할을 할 것임을 시사합니다.